Eclipse Winery’s Layout of Filebased Repository¶
Related architectural decision records are ADR-0001 ADR-0002.
The general structure is ROOT/<componenttype>s/<encoded-namespace>/<encoded-id>/<resource-specific-part>.
Encoding is explained below.
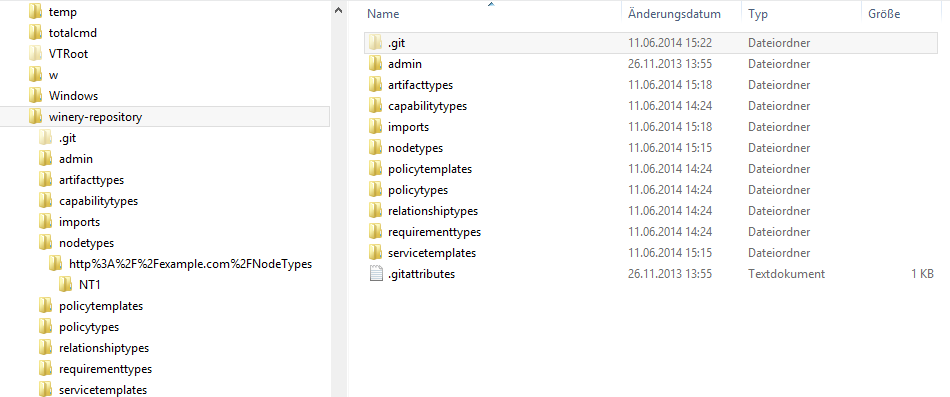
The figure below shows the root directory of the filesystem and the directory layout for the NodeType NT1.
Encoding¶
Encoding of directory and file names is done following RFC 3986. This makes the structure consistent to the URL structure (cf. REST API).
The URL encoding is necessary as some letter allowed in namespaces (e.g. ., :, ;, /) and IDs are not allowed on all operating systems.
IDs are NCNames, which are based on XML 1.0 Names, which in turn allows nearly all unicode characters.
Therefore, each namespace and ID is URL encoded when written to the filesystem and URL decoded when read from the filesystem.
More information on encoding is given at Encoding.
Typical layout¶
Typically, all definitions children have the path componenttype/ns/id.
The component type is nodetypes, relationshiptypes, servicetemplates, …
ns is the namespace.
It is stored encoded (see above).
id is the XML id of the component.
It is stored encoded (see above).
For instance, the NodeType NT1 in the namespace http://www.example.com/NodeTypes is found in the directory nodetypes/http%3A%2F%2Fexample.com%2FNodeTypes/NT1.
The content of the Definitions is stored in NodeType.tosca.
The resource-specific part typically is a file named <componenttype>.tosca.
It contains the Definitions XML file where all the data is stored.
Files may be added to artifact templates.
Therefore, a subdirectory “files” is created in ROOT/artifacttemplates/<encoded-namespace>/<encoded-id>.
There, the files are stored.
Directory imports¶
This directory stores files belonging to a CSAR. That means, when a definitions points to an external reference, the file has to be stored at the external location and not inside the repository.
Directory layout of the imports directory¶
imports/<encoded importtype>/<encoded namespace>/<id>/
In case no namespace is specified, then __NONE__ is used as namespace.
Handling of that is currently not supported.
id is a randomly generated id reflecting a single imported file.
Inside the directory, a .tosca is stored containing the import element only.
In the future, this can be used to contain the extensibility attributes, which are currently unsupported.
location points to
i) the local file or
ii) to some external definition (absolute URL!)
Currently, (ii) is not implemented and the storage is used as mirror only to be able to a) offer choice of known XML Schema definitions b) generate a UI for known XML Schemas (current idea: use http://sourceforge.net/projects/xsd2gui/)
Typically, all definitions children have the path type/ns/id.
We add imports before to group the imports.
The chosen order allows to present all available imports for a given import type
by just querying the contents of <encoded importtype>.
Handling of the extensibility parts¶
Handling of the extensible part of tImport is not supported.
A first idea is to store the Import XML Element as file in the respective directory.
Special treatment of XSD definitions¶
Knowing the definitions for a QName¶
Currently, all contained XSDs are queried for their defined local names and this set is aggregated.
The following is an implementation idea:
Each namespace may contain multiple definitions.
Therefore, each folder <enocoded namespace> contains a file import.properties,
which provides a mapping of local names to id.
For instance, if theElementis defined in myxmldefs.xsd (being the human-readable id of the folder),
index.properties contains theElement = myxmldefs.xsd.
The local name is sufficient as the namespace is given by the parent directory.